Here is all the story in English...
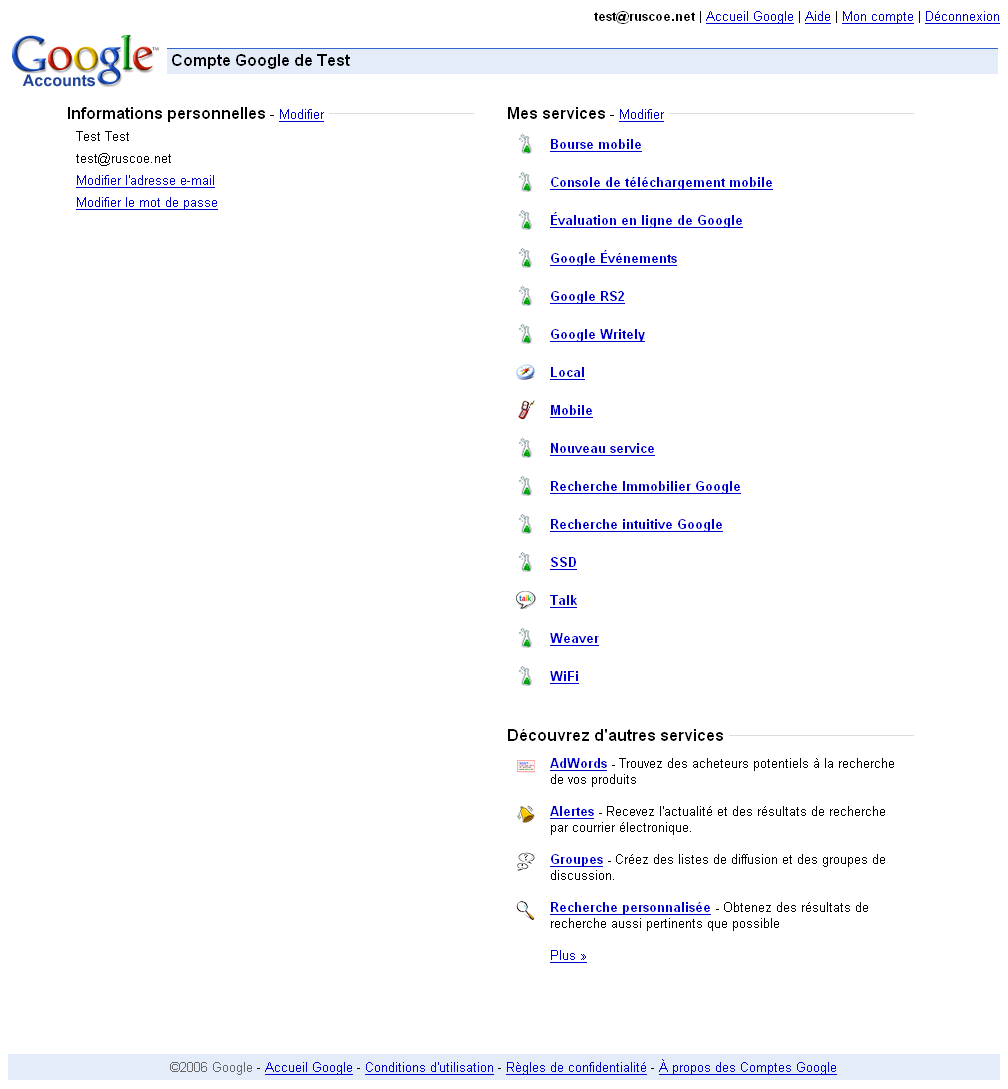
Cet article fait suite à mon billet sur Google RS2, qui tentait d'éclaircir deux des mystérieux services de Google révélés par Tony Ruscoe et repris par Zorgloob en français. Noms de code : Google RS2 et Google Weaver.
J'avais consacré tout le corps du billet au premier, à mon avis un nom de code pour décrire un service de traduction automatique des flux de syndication (RSS), ayant vocation à traduire à la volée des fils RSS ou de podcasts de/vers n'importe quelle langue, et un simple post-scriptum à Weaver :
D'après moi, ce n'est ni une allusion au tisserand (traduction de weaver en français) ni à Google Health, mais à Sigourney Weaver dans Futurama (in Love and Rocket), qui double un personnage parodiant HAL 9000, le Supercomputer, « ordinateur exceptionnel doué d'intelligence et de parole », dans 2001 : l'odyssée de l'espace.Or les observateurs de Google savent que HAL 9000 (h9) est un concept cher à Larry Page et Sergey Brin, qu'ils nomment volontiers The Ultimate Search Engine, concept auquel j'ai décidé de m'intéresser pour mieux comprendre ce à quoi ils se réfèrent par cette appellation de moteur de recherche ultime.

Diapositive n° 131 du Google Inc. Factory Tour du 19 mai 2005.
* * *
Les premières traces auxquelles j'ai pu remonter datent du 29 novrembre 2002, Paul fêtait le 1er anniversaire de sa joyeuse vie :

et Outre-Atlantique, Spencer Michels interviewait différentes personnalités du Net, dont les deux compères fondateurs de Google. Vidéo disponible ici :
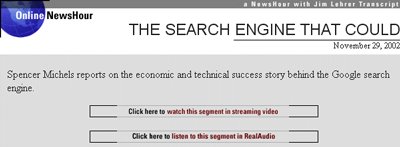
La retranscription des propos de Page & Brin nous donne des indications précieuses :
LARRY PAGE: And, actually, the ultimate search engine, which would understand, you know, exactly what you wanted when you typed in a query, and it would give you the exact right thing back, in computer science we call that artificial intelligence. That means it would be smart, and we're a long ways from having smart computers.Je crois que nous tenons ici l'explication précise du nom de code Weaver dans ces mots de Sergey Brin : « Hal ... pourrait disposer d'une quantité énorme d'informations, en recomposer le puzzle et les rationaliser. Ceci étant, il est à espérer qu'il n'attrapera jamais le même bogue que Hal 9000, qui finit par tuer les occupants du vaisseau spatial Discovery. Nous y travaillons, et je crois que nous sommes déjà sur la bonne voie... », puisque, dans Futura, Sigourney Weaver doublait un robot parodiant justement les travers de Hal !
SPENCER MICHELS: Sergey Brin thinks the ultimate search engine would be something like the computer named Hal in the movie 2001: A Space Odyssey.
SERGEY BRIN: Hal could... had a lot of information, could piece it together, could rationalize it. Now, hopefully, it would never... it would never have a bug like Hal did where he killed the occupants of the space ship. But that's what we're striving for, and I think we've made it a part of the way there.
* * *
The Ultimate Search Engine, selon Larry Page :
Le moteur de recherche ultime comprendrait précisément ce que vous voulez lorsque vous lui soumettez une requête, et vous donnerait la réponse exacte en retour, ce qu'on appelle l'intelligence artificielle en sciences de l'information. Ce qui signifie qu'il serait intelligent, et nous avons encore un long chemin à faire avant d'avoir des ordinateurs intelligents.Je rappelle la date de l'interview : 29 novembre 2002.
Intelligence artificielle, on monte en puissance. Ce même Larry Page est d'ailleurs revenu sur ces thèmes chers à Google il n'y a pas longtemps, le 23 mai dernier à Londres, lors de la conférence Zeitgeist 06 : l'IA pourrait vite devenir une réalité, d'ici quelques années (AI could be a reality within a few years). Peter Norvig n'est-il pas un expert en IA ?
Selon les propos rapportés de Page, voici quelques-unes de ses déclarations :
People always make the assumption that we're done with search. That's very far from the case. We're probably only 5 percent of the way there. We want to create the ultimate search engine that can understand anything ... some people could call that artificial intelligence.Alors, Google, un simple moteur de recherche ?...
Et d'ajouter : ...a lot of our systems already use learning techniques.
(Les gens supposent toujours que nous avons déjà fait le tour de la question de la recherche. Or c'est très loin d'être le cas. Nous n'en sommes probablement qu'à 5% du chemin qu'il nous faudrait accomplir. Ce que nous voulons, c'est créer le moteur de recherche ultime, LE moteur de recherche, capable de TOUT comprendre, ce que d'aucuns nommeraient l'intelligence artificielle... Nombre de nos systèmes utilisent déjà des technologies d'apprentissage.)
P.S. Parmi les services dévoilés par le scoop de Tony Ruscoe se trouve un sybillin Google Guess. Je ne sais pas quel sera le leur, mais vous connaissez déjà le mien ;-)
En attendant, j'espère que vous aurez observé la différence de regard entre Hal et Paul : Hal a l'œil cyclopique d'un lapin albinos, tandis que les yeux de mon fils ont la couleur et la profondeur des océans...
N.B. Merci à Jean-Baptiste Boisseau, traducteur français de What is Web 2.0, l'article fondateur de Tim O'Reilly, lecteur assidu et attentif qui a remarqué mon erreur d'interprétation des mots de Page :
Les gens pensent toujours que Google = recherche. Loin s'en faut. La recherche ne représente probablement que 5% de ce que nous faisons.Or comme je lui ai répondu en le remerciant, j'ai écrit ce billet animé par le sentiment de l'urgence. Carpe diem. Je ne voulais pas "perdre l'instant", tellement cette histoire me paraît énorme et que personne n'en parle. Sauf Adscriptor. Certes, si Search Engine Watch avait évoqué Google RS2 et Google Weaver/h9 dans l'article que Danny Sullivan publie aujourd'hui sur le sujet, l'impact serait tout autre et l'info ferait le tour du Web en moins de temps qu'il n'en faut pour le dire :-)
 Actualités, Google, Weaver, AI, IA, intelligence artificielle, Google h9, h9, Hal 9000, Ultimate Search Engine, OR, outil de recherche, moteur, moteur de recherche, Google RS2, RS2, laboratoire de traduction, laboratoire de réflexion, Internet
Actualités, Google, Weaver, AI, IA, intelligence artificielle, Google h9, h9, Hal 9000, Ultimate Search Engine, OR, outil de recherche, moteur, moteur de recherche, Google RS2, RS2, laboratoire de traduction, laboratoire de réflexion, Internet