
Deuxième volet de cet article (trois mois plus tard)
Évolutions...
La réalité de la traduction automatique en 2014
[MàJ - 23 octobre 2007] Un an et demi après la rédaction de ce billet, Google abandonne Systran au profit de son propre système de traduction. Cf. Google, traducteur automatique.
* * *
La puissance de Google est vraiment impressionnante ! La lecture d'un article de ZDNet me permet de revenir sur l'un des aspects de Google que j'avais déjà découvert lors de la présentation 2006 d'Eric Schmidt aux analystes financiers (ce n'était que le mois dernier, et pourtant j'ai l'impression qu'un an a déjà passé !) et qui m'avait intrigué : les ambitions annoncées de Google dans la traduction automatique (lire en fin de diapo 3).
Or un billet paru avant-hier sur le blog du centre de recherche de Google nous en dit plus :
« Because we want to provide everyone with access to all the world's information, including information written in every language, one of the exciting projects at Google Research is machine translation. » (Puisque notre mission consiste à permettre à quiconque d'avoir accès à toute l'information mondiale, notamment l'information écrite dans toutes les langues, l'un des projets les plus ambitieux que conduit notre centre de recherches porte sur la traduction automatique.)Depuis plus de 20 ans que je lis des tonnes de textes sur la traduction en général, et sur la traduction automatique en particulier, je peux vous dire que le sujet m'intéresse !
De la machine à traduire au phonétographe (ancêtre de la dictée vocale), les premières recherches sur la traduction automatique datent de l'après-guerre et précèdent de plus d'une décennie le développement d'Arpanet. Aujourd'hui on parle plus volontiers de traitement automatique des langues, ou de traitement automatique du langage naturel : TAL / TALN. À ne pas confondre avec les logiciels de TAO, ou traduction assistée par ordinateur, que nous utilisons quotidiennement en traduction professionnelle.
À l'heure actuelle, sur Internet, les systèmes de traduction automatique sont nombreux, vous en trouverez un bon aperçu ici, même si Christophe Asselin devra bientôt modifier son info sur l'outil de traduction de Google (Google utilise la technologie Systran), également intégré dans la barre d'outils de la firme.
En gros, Systran (System Translation), qui est à l'origine de tout le système de traduction automatique de l'Union européenne, excusez du peu !, fait appel à une technologie à base de règles (très sommairement : règles morphologiques, syntaxiques, sémantiques, grammaticales, règles heuristiques de rattachement pour associer les termes entre eux, règles logiques, etc. etc.) appliquées à des vocabulaires et des grammaires définis.
Google, en revanche, a choisi une autre approche :
« (W)e feed the computer with billions of words of text, both monolingual text in the target language, and aligned text consisting of examples of human translations between the languages. We then apply statistical learning techniques to build a translation model. We have achieved very good results in research evaluations. »qui consiste à gaver les machines de milliards de mots de texte (ce n'est pas la matière première qui lui manque !), ce qu'on appelle la linguistique de corpus (parallèles, alignés ou non), en associant des corpus (ou corpora pour les puristes) monolingues à des bi-textes (en prenant par exemple un site bilingue, ou tri- ou n-lingue, dont les textes sont segmentés puis alignés afin de fournir une mémoire de traduction) pour y appliquer ensuite des techniques d'apprentissage statistiques permettant de construire des modèles de traduction.
Et c'est là où Google est très fort, puisque, dernier arrivé dans ce domaine (où les places sont chères, par ailleurs), il se classe premier en devançant IBM, etc., et en se détachant très nettement de Systran, aussi bien pour la paire linguistique chinois-anglais :
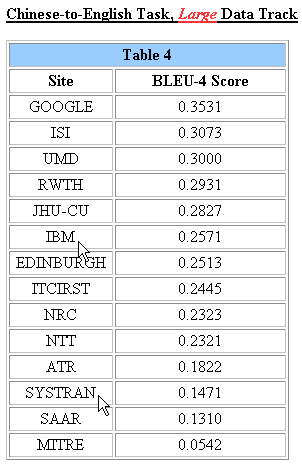
qu'arabe-anglais :
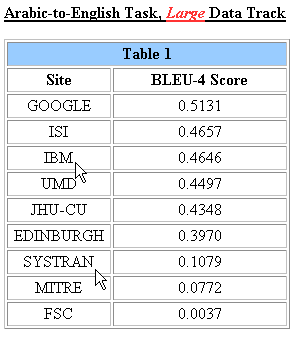
Voir les résultats officiels de l'évaluation sur la traduction automatique faite par le National Institute of Standards and Technology : NIST 2005 - Machine Translation Evaluation Official Results, dont une prochaine édition aura lieu dans deux mois, à suivre donc, comme nous le conseille Google en concluant le billet mentionné plus haut : do stay tuned for more exciting developments.
Pour sûr qu'on va rester « branchés ». Quand je vous parlais de la puissance de Google, vraiment impressionnant !

Partager sur Facebook
[MàJ - 15 juin 2006] Voici deux exemples pour vous donner une idée des résultats de la TA :
1. En consultant mes statistiques, j'ai vu que mon billet sur la dérive publicitaire sur Internet et les incohérences de Google avait été traduit par un visiteur américain sur l'outil de TA de Yahoo (Babelfish). Or une partie de ce billet étant une traduction d'un article paru sur The Motley Fool, j'ai trouvé intéressant de comparer l'original en anglais et sa retraduction du français à l'anglais. Le résultat me semble assez probant :
| Mon billet traduit par Yahoo Babelfish | Extrait de l'article original de Seth Jayson |
| Did you already make a research on Internet lately ? Then you will undoubtedly have observed the lack of quality of the results, including at the competitors of Google such as Yahoo! or Ask.com ? And their new design changes nothing there. I am pained by it as much as you. Me also I remained wedged hours and hours in the reels of these farms of bonds, these splogs and other " scraper sites " : sites which seem to have contents, (...), whereas actually, generally it is recycled material coming without their knowledge of other content providers, assembled by automated processes. | Any of you try searching lately? Notice the astounding lack of quality across the board, even at revamped competitors like Yahoo! (Nasdaq: YHOO) and IAC/InterActiveCorp's (Nasdaq: IACI) Ask.com? I feel your pain. I, too, have spent hours stuck in the revolving door of link farms, splogs, and scraper sites. These sites look like they contain content, (…). If there is some content there, it's often recycled material from other providers, compiled by an automated process. |
| The hurluberlus which create this kind of sites have one objective : you to bring to click on the sponsored bonds of Google AdSense. | The jokers who create these sites have one goal: Trying to get you to click on a Google AdSense link. |
| Naturally, these sites do not respect of anything the commercial conditions provided by Google, which does not prevent that they hatch per million. Make just a research on " adsense ready web site " and you will have an idea of this miteuse industry, as discrete as an elephant in a porcelain store, which extracts a maximum of profits from the phenomenon. | Of course, such sites run contrary to Google's terms of service, but that hasn't stopped zillions of them from popping up. In fact, a search on "adsense ready web site" will give you a glimpse of the often-sleazy, bigger-than-a-cottage, scraper-site industry that's sprung up to try to capitalize on the phenomenon. |
| How Google is it killing goose that lays the golden eggs. | How Google killed the golden goose. |
| The problems are numerous, and all the éradiquer could be expensive Google (when well even it would not be impossible). The first concerns the good old man plagiarism. | There are multiple problems here, all of which will be costly (if not impossible) for Google to eradicate. The first issue is good old-fashioned thievery. |
| The majority of these Spam boxes do not have that to attract the barge cliquor, but also to facilitate to the fraud with the clicks on a large scale (...) Besides the public generally the purpose of no idea is from what occurs, even if the Net surfers more informed a little are well-informed. We are unaware of of them only the true proportions. Of aucuns advance a rather restricted percentage of clicks; others say half straightforwardly. In any event, Google, which has very to lose if the things are as badly as certain journalists citizens denounce it, minimizes the figures considerably. | Many of these spamsites are set up not just to catch us individual clickers, but also to facilitate larger-scale click fraud (...)Most of the public is entirely clueless about this situation, but people who pay attention to the space know this problem exists. Only its extent is unknown. Some say low teens as a percentage of clicks; others shoot for half. Of course, Google, which has a ton to lose if things are as bad as some outspoken Netizens believe, consistently lowballs the number. |
| Another factor facilitating this explosion of spammé contents and fraud to the clicks is the seizure of Google on the level of research on Internet, which one can roughly speaking estimate at 60%, in fact a quasi-monopoly. For as much, the consistent argument with saying that the market is enough large to be corrected all alone on the matter is somewhat naive. Without competition and information, the markets do not correct anything the whole, and I do not think that there are today serious competitors able to make the weight. For the moment. | The other enabler for the explosion of spam content and click fraud is Google's roughly 60% stranglehold on Web search, which gives it a pretty effective monopoly. That's why I find the "self-correcting market" arguments regarding click fraud more than a tad naive. Markets don't correct without competition and information, and I don't think there's enough of either here to make a difference. Yet. |
| Take the case of the advertisers ofAdWords which believe that their results are diluted because of the fraud to the clicks. Be sure that they know that the biddings on their key words should cost them less, but can be made hear ? And can they allow it when there are of them thousands and thousands of other loans to be paid more because: (A) they are unaware of all the problem ; (b) they know it only too, but are able thanks to the fraud with the clicks to recover a part of what they spend on other side ? | Take AdWords advertisers who believe their results are being watered down by click fraud. Sure, they know they should bid lower on keywords to try to reflect that, but are they going to do it? Can they afford to, with so many others out there who bid high because (a) they don't know about the problem, or (b) they know much more than they should, and they're able to use click fraud to recoup some of what they're paying out? |
| I do not know the answers, and nor even all the questions. But if the problem is as serious as some fear it, it is all the model of income set up by Google which could suffer from it, even the whole of the business of the pay-per-click. While waiting for the explosion of the farms of bonds and the splogs shows clearly that the fraud with the clicks is juicy and flourishing, at the expense of all the Net surfers. Except of Google. For the moment, there still. | I don't know the answers -- or even all of the questions. But if this problem is as bad as some fear, it could eventually put a major crimp in Google's entire revenue model, if not the entire pay-per-click business. I would argue that the explosion of link farms and spamblogs is pretty decent evidence that the click-fraud biz is not only alive and well, but also thriving at the expense of all of us. Except Google. For now, anyway. |
| Never more ! | No mas! |
| One can believe or not that all these sites bourriels which make trade of AdSense are honest or defrauders in mass, but me that of which I is sure it is that it is necessary to thank Google for this situation. There is indeed no reason to put on line this kind of sites if one cannot draw an income thanks to the model from it from business set up by Google. And with Yahoo! and the other loans to enter the dance, I do not believe that one will see the tendency to be reversed as soon as. | Whether or not you believe that the junk sites out there peddling AdSense ads are honest commerce or capitalizing on large-scale click fraud, there's little doubt in my mind that we've got Google to thank for it. There's simply no reason for people to set up these sites if they can't skim dough via third-hand revenue sharing enabled by Google's business model. With Yahoo! and others set to get in on the same gig, I don't think we'll see this trend abate. |
| I hope only that all that predicts of a return to good old days, now that the blogosphère am likely to lose always more his importance, considering whom it starts to be co-opted by all the traffickers of AdSense and to be diluted quickly. Result : the information providers known for their qualite/fiability - of which much is undoubtedly blogs - will gain there in importance. And as soon as they carry out the capacity of their information, they will want less and less that Google money plunders them and makes on the back of the reputation which they will have put such an amount of labour and energy to be built. | I think that bodes for a return to the old days -- that the blogosphere that's being so rapidly diluted and co-opted by these AdSense shenanigans will become a lot less important. As a result, trusted information providers -- and some will doubtlessly be blogs -- will become more important. As they realize the power of their information, they'll be a lot less willing to allow Google to skim dollars off the content and reputation they've worked to build. |
2. Vous pouvez également consulter le site d'assistance de Microsoft, où « les fiches d'aide rédigées en anglais sont accessibles dans d'autres langues grâce à la traduction automatique «brute» (sans révision humaine). Ce n'est pas d'une qualité extraordinaire mais généralement ça suffit amplement à dépanner l'utilisateur lambda. Pour un traducteur, travailler à partir de cette traduction automatique ne me semble pas si différent que de travailler à partir de mémoires de traduction avec correspondance approximative (fuzzy matching). » Source : Eurêka.
Suite : Google RS2, traducteur automatique de troisième génération
Évolutions...
 Google, Systran, Traduction automatique, traduction, TA, laboratoire de traduction
Google, Systran, Traduction automatique, traduction, TA, laboratoire de traduction
6 commentaires:
La rumeur dit que c'est justement la bible (entre autres) qu'ils ont fournit en entrée, car la traduction est assez bonne dans chaque langue. Qu'en pensez-vous ?
Bonjour,
J'en pense que comme toutes les rumeurs, il y en a des vraies et des fausses, et que celle-ci appartient à la deuxième catégorie. Les ressources utilisées sont indiquées ici, cliquer sur les liens « resources » pour approfondir.
Cordialement,
JML
j'aime bien l'outil de traduction de Google, mais des fois j'ai été sidéré par sa façon de traduire certains noms propres. De mettre le nom d'un journaliste à la place d'un autre. Très étrange.
Joseph,
Pour l'instant l'outil Google disponible au grand public est le traducteur Systran, j'attends avec impatience que Google nous sorte son propre outil. C'est peut-être prématuré pour l'instant, mais je suis sûr que ça viendra bien un jour, surtout lorsque Google s'attaquera sérieusement à fidéliser son prochain milliard d'utilisateurs.
J-M
Perso, mon retour d'expérience (seulement 15 jours il faut l'avouer) semble m'indiquer que l'outil de Google est très bon pour la traduction vers l'anglais (essayé à partir du russe, du portugais, de l'espagnol et de l'allemand). Mais pas meilleur que les autres pour la traduction vers d'autres langues (en particulier vers le français). Pour l'instant ?
Alain,
J'ai fait un comparatif ici et personnellement, je trouve qu'il y a aussi une amélioration avec le français.
Cordialement,
Jean-Marie
Enregistrer un commentaire