Récapitulatif des faits
Du cas particulier au cas général
1. Qu'est-ce que la crédibilité ?
2. Quand y a-t-il asymétrie de la crédibilité ?
Réplique à Jean de Chambure, Directeur Médias de l'Atelier
* * *
Récapitulatif des faits
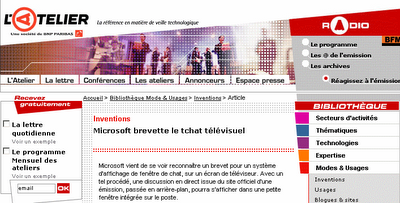
La semaine dernière, j'expliquais dans le détail une histoire de plagiat manifeste commis par l'Atelier, qui se résume en deux images. L'info sortie par Silicon le 26 juillet 2004 :

L'actu publiée par l'Atelier le 27 avril 2006, près de deux ans plus tard :

Les parties en jaune sont entièrement pompées. Suite à la publication de mon billet, le 28 avril j'ai envoyé deux courriels pour demander des explications - le matin à Jean-Michel Billaut pour l'Atelier, et dans l'après-midi à la rédaction de Silicon -, dont voici la teneur :
Bonjour Monsieur Billaut,Or 5 jours ont passé, et toujours aucune réponse, ni d'une part ni de l'autre. C'est bien beau de mettre une page de contacts, mais encore faudrait-il daigner répondre. Probable que M. Billaut est trop occupé à tourner ses vidéos (il a sorti 4 nouveaux billets durant ce même délai) pour avoir le temps d'être à l'écoute. Quant à Silicon, apparemment ils s'en foutent !
Je me permets de vous adresser ce courriel après avoir vu que vous étiez président d'honneur de l'Atelier, dont je suis les actus quotidiennes avec beaucoup d'attention. Or j'ai été assez déconcerté par ce que j'ai découvert hier soir et que j'expose dans ce billet. C'est difficile à comprendre et j'espère que vous ou quelqu'un de l'atelier voudra bien réagir, tout au moins pour expliquer ce qui s'est passé, car un épisode comme ça peut vous faire douter durablement de la fiabilité d'une source d'information. Je visite assez régulièrement votre blog, et je suis sûr que vous comprendrez ce que je peux ressentir en tant que blogueur. Cordialement,...* * *Rédaction de Silicon - Objet : réaction - Bonjour,
Je voudrais vous demander votre avis sur un épisode qui m'a quelque peu déconcerté hier soir et que j'ai décrit ici. J'ai contacté l'Atelier mais personne ne m'a encore répondu.
Cordialement,...
Voilà donc une affaire qui a le don de m'énerver, et beaucoup ! Maintenant, indépendamment de l'évolution du cas particulier, j'ai envie de généraliser pour élargir le cadre du débat, plus que jamais dans l'air du temps au moment où il est question d'instaurer une soi-disant « signature certifiée ». J'y reviendrai... [Début]
Du cas particulier au cas général
Je considère cette affaire grave pour plusieurs raisons :
- L'Atelier, émanation d'un des premiers groupes bancaires français (centre de veille technologique de BNP-Paribas), a pignon sur rue et jouit d'une réputation de sérieux et de qualité. Jusqu'à son slogan qui en dit long : « La référence en matière de veille technologique ».
Or je suis désolé, mais quand on « sort une information », a fortiori plagiée, qu'on veut faire passer pour récente alors qu'elle date de 2 ans ou peu s'en faut, ce n'est plus de la veille, c'est de la vieille ! C'est du dépassé, de l'obsolète, du caduc, du suranné, de l'usagé, du has been, du ringard ou tout ce qu'on veut. Surtout sur Internet, où rien n'est plus facile que de recouper l'information, évanescente et volatile par excellence ! - Qui plus est, je ne sais pas combien ils ont d'abonnés à leur lettre d'info quotidienne, mais ça fait du monde (sûrement sans aucune mesure avec mes 55 lectrices et lecteurs de la journée d'hier) qui va lire ça sans se poser la question, à juste droit, en avalant pour argent comptant ce qui n'est que du réchauffé (voire du refroidi, depuis le temps).
- Un pareil épisode sème un doute durable (je parle pour moi) sur la fiabilité de la source, et plus encore dès lors qu'on ne daigne pas répondre à qui vous demande des explications, dont la moindre (nous nous sommes trompés, il s'est passé ci, il s'est passé ça, veuillez nous excuser) serait infiniment préférable à un silence interprétable au mieux comme du je-m'en-foutisme, au pire comme de l'indifférence, voire de la condescendance, coupable dans tous les cas.
- En une formule, il y a faute caractérisée, tromperie sur la marchandise, et plus la source fait autorité, plus le préjudice est grand ! [Début]
Asymétrie de la crédibilité dans l'information
Habituellement, il est souvent question d'asymétrie de l'information, mais, à ma connaissance, jamais d'asymétrie de la crédibilité de l'information. Je vais essayer de définir cette notion telle que je la conçois.
1. Qu'est-ce que la crédibilité ?
D'après le petit Robert, très sommairement, la crédibilité c'est « (c)e qui fait qu'une personne, une chose mérite d'être crue ».
Mais sur Internet, c'est beaucoup plus que ça ! C'est un concept clé, d'une importance majeure. Au centre de toute stratégie, de toute politique de communication. Ça vaut de l'or, la crédibilité, ou mieux encore : ça n'a pas de prix !
La crédibilité c'est d'abord une affaire de confiance, et aussi de cohérence. La crédibilité c'est un dialogue, dont les interlocuteurs pèsent et soupèsent tour à tour la qualité de la parole donnée, et reçue, où la première chose à faire est de se montrer capable d'honorer sa parole dès lors qu'on veut gagner la confiance de quelqu'un. La crédibilité, ça se mérite.
Dans une excellente étude intitulée : « Proposition d’une échelle de mesure de la crédibilité d’un signe de qualité », F. Larceneux s'appuie sur plusieurs auteurs pour énumérer « Les composantes de la crédibilité » (c'est moi qui mets en évidence) :
D’après Dean (1998), la littérature sur la crédibilité de la source a permis d’identifier trois dimensions d’attribution : l’expertise, la capacité à inspirer confiance et la valeur sociale perçue. En fait, de manière plus précise, pour être perçue comme crédible et prise en compte dans le processus de décision du consommateur, une source d’information doit paraître aux yeux du consommateur fiable, compétente et sincère (Hovland et Weiss, 1951). Ces trois dimensions se construisent autour d’un certain nombre d’antécédents de la crédibilité. Ainsi, la revue de littérature suivante est structurée selon les antécédents de la crédibilité dans les différents champs disciplinaires autour de ces trois dimensions plus une : (1) la confiance, (2) la sincérité (l’honnêteté, l’indépendance commerciale, la capacité à inspirer confiance, les bonnes intentions), (3) la compétence (l’expertise reconnue, la nature de l’émetteur), et (4) la fiabilité (la puissance financière, l’identification de l’émetteur, la vulnérabilité aux sanctions des consommateurs, les investissements en réputation, le fait d’exposer ses ventes au risque et le degré de diversification).Ce n'est pas pour rien qu'il y a des tonnes de littérature sur la crédibilité dans le marketing, la publicité, où c'est une valeur fondamentale pour les marques, les produits, etc.
Quid de l'information sur le Web, donc, où l’info peut être considérée un produit (à mon avis c’est même le PREMIER produit disponible sur Internet en abondance) ? Pour faire un parallèle avec la pub, je citerais Ries & Ries, selon lesquels le plus gros problème de la publicité aujourd’hui, c’est qu’elle manque de crédibilité : tout simplement les gens ne croient plus les annonces publicitaires qu’ils lisent (ou voient ou entendent), et l’un des facteurs qui concourt à générer ce manque de crédibilité c’est le volume exponentiel de la pub. Trop c’est trop, trop de pub tue la pub, pourrait-on dire à la mode de chez nous…
Advertising lacks credibility. People just do not believe what they read (or see or hear) in an advertisement. (...) Contributing to the credibility problem, of course, is the volume of advertising.Remplacez la pub par l'info, et vous avez « Trop c’est trop, trop d'info tue l'info, trop d'infos tuent l'info… »
D'où la nécessité de faire continuellement le tri dans cette profusion, de recouper, d'apprendre à discerner, structurer, hiérarchiser les signes, etc., pour crédibiliser l'info, au cas par cas. [Début]
2. Quand y a-t-il asymétrie de la crédibilité ?
La crédibilité - d’une source d’information dans le cas qui m’occupe – peut avoir deux origines : soit elle est objective, soit elle est subjective, avec en corollaire, soit elle est visible, soit elle est invisible :
- Même objective à la source, elle peut être perçue crédible ou non par la cible
- Même subjective pour la cible, la source peut être réellement crédible ou non
Il y a asymétrie lorsque :
- la source objectivement crédible est subjectivement perçue comme non crédible
- la source objectivement non crédible est subjectivement perçue comme crédible
- la source objectivement crédible est largement ignorée (il y a crédibilité sans notoriété / visibilité)
- la source objectivement non crédible est largement suivie (notoriété / visibilité sans crédibilité)
Où se situe l'Atelier parmi ces hypothèses ? J'espère qu'ils voudront bien nous donner une indication. Quoi qu'il en soit, ça restera un épisode à mettre au compte des antécédents... [Début]
P.S. Il est presque 13h à l'heure où je publie ce billet, l'information incriminée est toujours en ligne, et je n'ai reçu aucune réponse. Mais cette fois j'écris à tout le monde. Allons-y...
[MàJ - 16h] Bon, trois heures après avoir ma prise de contact, je viens de recevoir un courriel de Jean de Chambure, Directeur Médias de l'Atelier, m'expliquant ce qui s'est passé et me demandant de ne pas reproduire son message. Donc, acte.
Ceci étant, j'observe deux choses :
1. J'aurais préféré qu'il réponde publiquement, après tout ce n'est pas une affaire entre lui et moi, mais plutôt entre l'Atelier et son lectorat, dont moi, et peut-être vous. Qu'il s'excuse auprès de la rédaction de Silicon.fr, c'est la moindre des choses. Mais auprès de ses lectrices et de ses lecteurs, ça serait pas mal non plus.
2. Il réfute en bloc mon « long commentaire sur la crédibilité de l'information en tant que telle ». C'est son droit, mais je persiste et je signe. Comme je le dis dans mon article, j'ai voulu élargir le cadre du débat en passant du cas particulier au cas général, et l'asymétrie de la crédibilité de l'information est un problème réel sur l'Internet, qui ne concerne pas uniquement l'Atelier, mais toutes les sources d'information sur le Web, dont moi, et peut-être vous.
JML
* * *
[MàJ II - 19h30'] Ou comment s'en tirer par une pirouette :

Il suffit de rajouter quelques phrases bien senties :
Erratum : Microsoft brevette le tchat télévisuelNi vu ni connu, et c'est moi le méchant ;-) [Début]
Dans un article précédemment rédigé, nous avions oublié de citer la source de commentaires sur le sujet. Nos plus vives excuses auprès de notre confrère Silicon.fr pour cette erreur. Voici donc l'article corrigé. (...)
Déjà en 2004, nos confrères de Silicon en expliquaient le principe très simple : (...)
Et nos confrères de Silicon de noter les grandes ambitions que l'éditeur pourrait fonder sur ce brevet...
Tags : Actualités, veille, information, Internet, mensonge, vérité, plagiat