Google - eBay
MySpace
McAfee - SiteAdvisor
Préparez-vous à être submergés par une myriade de dépêches et d'analyses sur l'actualité dominante des jours à venir, j'ai nommé GBuy !
Google Wallet il y a presque un an jour pour jour, puis G-Money, GPay, Google Checkout (https://checkout.google.com/ renvoie pour l'instant vers votre compte personnalisé)...
[MàJ - 29 juin 2006] Exit GBuy, Google lance Checkout. En cliquant sur le lien ci-dessus que je vous donnais hier, vous arrivez sur la fenêtre de connexion suivante :

Google propose également une vidéo de présentation du service, cliquez sur l'image ci-dessous si vous souhaitez la visionner :

Comme vous pouvez le constater, le petit chariot bleu à gauche de l'URL, symbole de Checkout, indique que ce cybermarchand utilise le service de Google. Une façon supplémentaire de nous dire qu'il s'agit d'un site sécurisé, ce qui aura forcément un impact sur la navigation des internautes dès que le bassin d'utilisateurs prendra de l'ampleur et que le service montera en puissance. En outre, l'exemple choisi par Google nous montre un lien sponsorisé, mais il est à prévoir que les résultats organiques intégreront aussi le petit chariot. À suivre...
Enfin, pour l'instant, Checkout n'est disponible qu'aux États-Unis, même s'il est probable que la localisation (qui est déjà un atout majeur des Adsense) ne tardera pas...
* * *
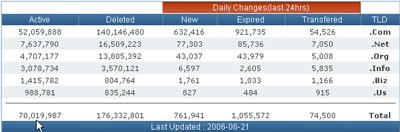
Donc, voilà plus d'un an que les observateurs, journalistes et blogueurs du monde entier se perdaient en conjectures sur ce qui a toujours été présenté comme une alternative à Paypal, sauf par ... Google : Mr. Schmidt also denied it would directly compete with PayPal. Mr. Schmidt said Google didn't intend to offer a "person-to-person, stored-value payments system," which many people consider a description of PayPal's service.On allait bientôt tout savoir, GBuy décortiqué, examiné sous toutes les coutures, etc. Ne comptez donc pas sur moi pour ajouter à la cacophonie. Je préfère me limiter à rappeler que Yahoo a déjà essayé PayDirect, un service semblable, sans grand succès. Yahoo qui a obtenu il y a peu un brevet dénommé Systems and methods for implementing person-to-person money exchange (à ne pas confondre avec Systems and methods for implementing person-to-person international money exchanges !)...
(M. Schmidt dément que [ce service] serait en concurrence directe avec PayPal. Selon lui, Google n'entend pas offrir un "système de prépaiment individualisé", une définition que beaucoup considèrent comme une description de ce qu'est PayPal.)
Après PayDirect, pourquoi pas Pay2PayDirect :-) [Début]
En attendant, Google vient de rendre GMail, Google News et quelques autres services accessibles depuis votre mobile...
 (Je ne dis pas "le mien", vu que le service n'est pas encore disponible en Italie...)
(Je ne dis pas "le mien", vu que le service n'est pas encore disponible en Italie...) En parallèle, je viens juste de m'apercevoir que Google a commencé à mettre des pubs aussi dans ses alertes :
 Voilà des mois que je les reçois et jamais aucune pub n'avait précédé les résultats, une situation qui a changé apparamment entre 10h19' et 13h14' aujourd'hui ! [Début]
Voilà des mois que je les reçois et jamais aucune pub n'avait précédé les résultats, une situation qui a changé apparamment entre 10h19' et 13h14' aujourd'hui ! [Début]* * *

Toujours pour ce qui concerne le couple Google - eBay, après la compétition et les infidélités d'eBay avec Yahoo, voici venue l'heure de la coopétition, ou coopération compétitive, puisque Google et eBay financent ensemble FON, afin de vendre des routeurs communautaires à ... 5 $/€ et de promouvoir le Wi-Fi gratuit ! Ça devrait en intéresser plus d'un...
Signalons au passage que Martin Varsavsky, le FON...dateur, fait partie du premier tour de table d'investisseurs qui ont permis de lancer Wikio, aux côtés de Loïc Le Meur, Jeff Clavier, Freddy Mini, Ouriel Ohayon et, bien sûr, Pierre Chappaz. Une affaire qui agite le landerneau du Web francophone pour d'autres raisons... [Début]
* * *
Maintenant, à propos de MySpace, je viens de lire cette déclaration dans une longue interview de Murdoch sur Wired, concernant Google :
I like those guys, but there’s a bit of arrogance. They could have bought MySpace three months before we did for half the price. They thought, “It’s nothing special. We can do that.”Soit moins de 300 millions $ !. Via GigaOm, Search Newz, Search Engine Journal. Même si selon d'autres sources :
Je les aime bien, même s'ils sont parfois un peu arrogants. Ils auraient pu acheter MySpace trois mois avant nous à moitié prix, mais ils ont dû croire “Rien de spécial, nous pouvons en faire autant.”
According to Michael Nutley of New Media Age Rupert Murdoch was told by Google Chairman Eric Schmidt that acquiring Intermix and MySpace would be “the best deal of his life.”Allez savoir s'il y a eu délit d'initié et quel est le vrai du faux ! Donc, apparamment, Google n'aurait pas su saisir à temps le virage "réseaux sociaux" ? Tout comme Microsoft n'a pas compris la portée de l'Internet à l'époque de Windows 95. Juste pour faire un parallèle...
D'après Michael Nutley, de New Media Age, Eric Schmidt, PDG de Google, aurait dit à Rupert Murdoch que faire l'acquisition d'Intermix et de MySpace pourrait bien être “la meilleure affaire de sa vie.”
Quant au problème de la protection des enfants et des adolescents sur MySpace et, d'une manière générale, sur les réseaux sociaux, hier à la Chambre des Députés U.S. a eu lieu une audition, pour celles et ceux qui comprennent bien l'
* * *
Ma deuxième mise à jour concerne McAfee - SiteAdvisor dont je vous parlais il y a un mois au sujet de la recherche sécurisée et de la mise en œuvre future d'un possible SafeRank, un avis jugé plausible par Bill Slawski (So, you may be right - some type of saferank could be part of the near future), qui est certainement bien plus expert que je ne le suis.
Or je viens juste de découvrir qu'une extension est disponible au téléchargement pour Internet Explorer ou FireFox. À tester pour une navigation sécurisée, faites-moi savoir vos commentaires si vous l'avez déjà essayé...
 [Début]
[Début]Tags : Actualités, Google, Google Wallet, Google Checkout, GPay, GBuy, PayPal, eBay, Fon, Yahoo, MySpace, McAfee, SiteAdvisor, Internet