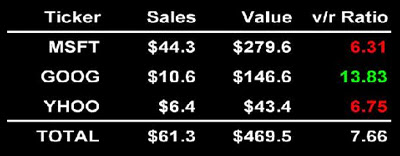
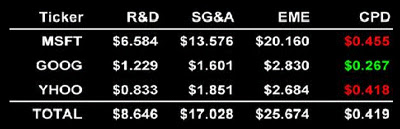
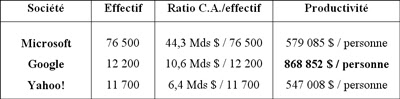
IntroductionLe brevet qui fait peurSur Internet, la gratuité est-elle gratuite ?* * *
IntroductionJe suis toujours très étonné de voir que les gens s'étonnent des implications infinies qu'a et qu'aura de plus en plus Internet sur nos vies privées. Et de voir des levées de bouclier plus ou moins étendues, plus ou moins consensuelles, contre l'espionnage et le profilage comportemental qui menacent le respect de nos libertés individuelles, de nos choix personnels et professionnels, de notre aptitude à décider, etc.
De même que
l'identité numérique est inévitable, le profilage qui en est le pendant naturel l'est tout autant pour les marchands. Car dès que nous nous connectons à Internet, nos faits et gestes sont traqués, pesés, soupesés, analysés, décortiqués, etc. Sachons-le !
Et ne soyons pas surpris : inutile de faire semblant de croire qu'on pourrait y échapper, inutile de s'indigner (attention, je ne dis pas que s'indigner n'est pas légitime, je dis que c'est inutile, nuance, même si je vais vous paraître désabusé...), les intérêts et les puissances en jeu - économiques et autres - sont trop considérables pour prendre en compte les attentes de l'internaute lambda, dont l'opinion a environ la même densité que la goutte d'eau dans l'océan...
Pour faire une métaphore, l'information aujourd'hui, c'est comme le pétrole il y a un siècle et demi, un gisement brut dont l'humanité se nourrira longtemps encore, et les effets collatéraux tels que le
réchauffement climatique n'ont jamais empêché les marchands d'imposer l'or noir au monde entier, ni de le rendre indispensable et irremplaçable alors même qu'il pourrait être remplacé. Substituez juste "réchauffement climatique" avec "respect de la vie privée" pour aller jusqu'au bout de l'analogie...
Fini le marketing de masse indifférencié, les techniques de pointe sont depuis longtemps déjà au
ciblage socio-démographique, au
profilage psychologique et comportemental (qui n'est plus l'apanage des seuls
criminels), au
géomarketing, etc. Et qu’on le craigne ou s’en offusque n’y changera rien. Depuis longtemps le cynisme et le pragmatisme des publicitaires ont pris le pas sur les bonnes vieilles valeurs d’antan, il faut en être conscients. Sous peine d’immenses et d’intenses désillusions, cruelles certes, mais qui ne changeront pas le cours de l’histoire pour autant.
Déjà, pour les gourous de l’Internet qui décident où, quand et comment placer leur pub pour qu’elle ait l’impact le plus fort et le taux de transformation le plus élevé, il y a longtemps qu’une somme d’individus ne fait plus une collectivité mais
un marché, ou plutôt
des marchés, autre abstraction bien commode par les temps qui courent. Et qu’on appelle ces individus internautes, utilisateurs, journalistes citoyens ou autres ne fait aucune différence.
Désormais, la segmentation sur Internet se fait tellement efficace que
la plus petite unité de découpage est l’individu, qui se trouve ainsi pratiquement dépecé, analysé sous toutes ses coutures et composantes, physiques, mentales, sociales, culturelles, économiques, publiques, privées, familiales, professionnelles, voire sexuelles, raciales et religieuses, etc.,
au point que chacun est un marché à lui tout seul, chacune un marché à elle seule. Le graal des marketers depuis la nuit des temps…
Qui ne vont pas se priver de continuer à archiver, trier, répertorier, géoréférencer, etc., une masse de données considérable, dont la croissance exponentielle fait passer la
loi de Moore pour de la
roupie de sansonnet.
Sans oublier que dans un avenir très proche la montée en puissance de la
téléphonie mobile, le déploiement mondial de la
biométrie et de certaines
FET (technologies futures et émergentes), mais aussi de l’
Internet des choses, tout cela permettra aux entreprises d’anticiper toujours davantage, voire d’inventer – au plus près (dimension géospatiale) et au plus tôt (dimension temporelle) – nos attentes, nos désirs, nos goûts, etc., avec une exactitude quasi-satellitaire, un niveau de précision jamais égalé à ce jour, et aujourd’hui encore bien moins que demain.
S'il ne fallait citer qu'un chiffre :

[
MàJ - 3 juin 2007 : l'
adaptation française de cette vidéo est maintenant disponible]
A fortiori, il n'y a pas que les entreprises. Faites confiance aux gouvernements et aux institutions de tous bords pour en faire autant. Avec notre accord ou sans. Du genre «
ennemis de l'État ». Les enjeux sont trops gigantesques pour qu'ils s'arrêtent à des détails aussi insignifiants que l'avis des personnes.
Pour employer un néologisme parlant,
nous serons vivisséqués et surveillés en permanence. Tout au long de notre existence, du berceau au tombeau. Qu’on le veuille ou non.
Donc si ce préambule est clair, nous pouvons entrer dans le vif du sujet.
[Début]* * *
Le brevet qui fait peurCet article couvait en moi depuis quelques mois déjà, mais c'est la lecture du billet de François Grisoni sur l'excellent
Googlinside qui en a été le déclencheur. Intitulé «
Le brevet qui fait peur », l'auteur s'inquiète de ce qu' «
il serait possible d'établir le profil psychologique d'un joueur sans interférer avec l'expérience de ce dernier... », offrant ainsi la possibilité «
effectivement très simple et sans doute particulièrement tentant(e) de croiser les données recueillies à l'aide de cette technologie aux informations déposées par le joueur lors de son inscription, rompant ainsi l'anonymat des statistiques. »
Donc, dans un premier temps j'ai voulu en savoir plus sur le dépôt (par BALUJA, Shumeet aux U.S. et par Google hors U.S.) du brevet n°
20070072676, intitulé «
Using information from user-video game interactions to target advertisements, such as advertisements to be served in video games for example » (
traduction officielle :
utilisation d'informations issues d'interactions de jeux vidéo utilisateur pour cibler des publicités telles que des publicités pouvant servir dans des jeux vidéo par exemple), qui décrit de manière assez détaillée un échantillon possible des emplois multiples que l'on peut faire des saisies/actions de l'utilisateur. Exemple avec le point 47 de la description :
User input may include user selections, user dialog, user play, etc. User selections may include, for example, one or more of characters, vehicles (e.g., a specific make of an automobile, car color, engine modifications, car modifications, etc.), tracks, courses or fields (e.g., a specific racetrack, a specific stadium, etc.), teams, players, attire, physical attributes, etc. There are many customizations a user may select from depending on the genre of the game. These selections may reflect the user's fondness, preferences, and/or interests. User dialog (e.g., from role playing games, simulation games, etc.) may be used to characterize the user (e.g., literate or illiterate, profane, blunt, or polite, quiet or chatty, etc.). Also, user play may be used to characterize the user (e.g., cautious, strategic, risk-taker, aggressive, non-confrontational, stealthy, honest, dishonest, cooperative, uncooperative, etc.).
François Grisoni nous fournit une traduction partielle (la partie en gras ci-dessus), qui donne une bonne idée de l'ambiance :
Les dialogues (par exemple dans les RPG, les simulations, etc.) peuvent être utilisés pour caractériser l’utilisateur (par exemple éduqué, profane, franc, poli, calme, etc.). De la même façon, la façon de jouer de d’utilisateur peut être analysée (par exemple courageux, agressif, évite les confrontations, discret, honnête, coopératif, indépendant, etc.).
Par conséquent, s'il est clair qu'on peut légitimement s'en inquiéter, il est tout aussi clair de voir que la stratégie globale des firmes va inexorablement dans ce sens, et que les quantités de plus en plus faramineuses de données qu'elles récoltent tous azimuts à notre sujet seront peu ou prou utilisées pour influer sur nos choix, nos actions, nos comportements, etc., la liste n'est limitée que par l'imagination.
Et même si les sociétés telles que Google cherchent constamment à nous
rassurer, il est évident qu'emmagasiner autant de données sans les exploiter serait
suicidaire pour une entreprise. La mise à disposition "gracieuse" de plus en plus de services destinés aux internautes n'a d'ailleurs pas d'autre but que de collecter et d'amasser nos données à des fins de traitement, de ciblage, etc. Ce qui nous amène à nous poser la question suivante...
[Début][
MàJ - 29 mai 2007] À propos de
Googlinside , voir la vidéo qu'ils ont réalisée. Même muet, il est parlant, ce
GMan...
* * *
Sur Internet, la gratuité est-elle gratuite ?La réponse est évidente : NON ! La seule justification de l'apparente gratuité sur Internet est qu'elle permet d'obtenir un avantage en retour, que ce soit en termes économiques, d'analyse, de positionnement, de pénétration, etc. Ce que les auteurs du rapport sur l'
économie de l'immatériel (PDF, 700 ko) appellent «
Le paradoxe de la "valeur gratuite" ».
Et au final de mieux capturer l' "utilisateur" dans les rets du filet, le Net, de la toile, le Web, du réseau, le Network, du réseau des réseaux, Internet ! Pour mieux le faire confluer, converger, consommer, etc.
Seul point commun, le préfixe con...Le jour de mon 49e anniversaire, il y a plus d'un an déjà, je sais :-(, dans un billet intitulé
Google : the Portal Strategy!, qui tentait de dresser un panorama détaillé de la galaxie de services grâce auxquels Google centralise de plus en plus de données précises sur les internautes, j'envisageais explicitement le rôle de
profileur de Google en ces termes :
Par conséquent dans cette logique, à terme plus ou moins rapproché, la prochaine étape consistera très probablement à s’éloigner de la catégorisation des annonces pour passer à leur individualisation. En bref :
fini les AdSenses ciblés, vive les AdSenses personnalisés !
Une (r)évolution qui me semble inéluctable, vu les ambitions affichées par Google : à partir du moment où la firme possède une énorme quantité d’informations sur vous et peut en extraire un profilage systématique et significatif, qu’est-ce qui l'empêchera de vous proposer des AdSenses en fonction de vos préférences ?
Concrètement, cela signifie que deux internautes faisant la même recherche sur le même Data Center de Google, à un instant donné, se verront proposer des AdSenses distincts dans les résultats, ciblés sur leurs centres d’intérêts, tous les produits et services destinés a priori à améliorer votre « expérience de navigation », dans le discours bien rodé de Google, servant naturellement à personnaliser les annonces à votre intention, évidemment différentes de celles du voisin.
Avec à plus ou moins long terme aussi, le risque danger que les résultats fournis deviennent de moins en moins neutres, objectifs, et de plus en plus orientés, pilotés, en fonction des intérêts des parties prenantes (voir les résultats de Google Base qui font déjà de l'ombre aux liens sponsorisés...). Car jusqu'à preuve du contraire, nous devons bien comprendre (et donc, ne pas confondre) qu’un moteur de recherches n’est pas un service public mais une entreprise privée, et commerciale, d’où les inévitables pressions pour « monétiser » ses produits et services et constamment améliorer le fameux ROI… Ça semble couler de source, mais le rappel n’est pas inutile !
Attention, je ne parle ici que des Adsense (sans évoquer la myriade d'autres usages possibles), non pas de leur personnalisation côté éditeur, au sens d’intégration et d’
optimisation des messages de pub dans votre site, mais bien de leur personnalisation côté Google, c’est-à-dire au niveau des Adsense servis par le moteur. Dont je considère qu'avec sa nouvelle accroche
subliminale,
Universal Search, Ads & Apps, tout est dit.
Ainsi je ne peux que confirmer la conclusion que je tenais dès mars 2006 :
Le client est ROI, certes, mais roi de quoi ?...
Alors,
Google profileur en série, oui ou non ? Qu'en pensez-vous ?
[Début]P.S. L'appellation de "profileur en série" dont j'affuble Google vaut tout autant pour les acteurs majeurs du Web, mais pas seulement, d'AOL à Microsoft, de Verisign à Yahoo!, en passant par GoDaddy ou qui vous voulez, il est important de le préciser...
[Début] Actualités
Actualités,
Google,
Google Strategy,
stratégie de Google,
GYM,
identité,
gestion de l'identité,
identité 2.0,
identité numérique,
identité virtuelle,
gestion de la réputation,
profilage,
Internet